
Imaginons que vous deviez analyser un jeu de données de plusieurs milliards de lignes pour un projet de Data Science. Quel outil choisiriez-vous ? Si vous êtes comme beaucoup de Data Scientists, vous pensez probablement à Pandas. Mais imaginez qu'un outil plus rapide et plus léger pouvait faire le travail en un temps record ? Voici où DuckDB entre en scène !
DuckDB est une base de données en colonnes optimisée pour le traitement de données analytiques massives, offrant des performances élevées tout en restant légère et facilement intégrable dans des environnements comme Python et R, des langages essentiels pour les projets de Data Science. Bien qu’il ne soit pas le choix principal pour des applications classiques de BI, où des solutions comme Power BI ou Talend sont plus courantes, DuckDB se distingue par son efficacité pour gérer des datasets volumineux, souvent rencontrés dans ce domaine.
Mais DuckDB est-il vraiment plus rapide que des bibliothèques populaires comme Pandas, qui reste souvent le choix par défaut pour de nombreuses tâches d’analyse de données ? Pour mieux comprendre les points forts de DuckDB, examinons quelques aspects clés qui pourraient justifier son intérêt dans ce contexte :
- Vitesse de traitement : Grâce à son système de stockage en colonne et à des algorithmes optimisés pour les bases de données, DuckDB est capable de traiter les données beaucoup plus rapidement.
- Évolutivité : Contrairement à Pandas, qui peut atteindre ses limites mémoire avec de gros datasets, DuckDB semble plus adapté pour traiter de grandes quantités de données sans ces contraintes.
Pour voir si DuckDB tient vraiment ses promesses, nous allons passer à la pratique et comparer ses performances à celles de Pandas dans un test concret.
Méthodologie du test
Pour ce comparatif, nous avons généré un fichier CSV assez conséquent sur lequel nous réaliserons plusieurs opérations qui représentent des étapes classiques dans le traitement de données volumineuses. Le chargement simule le temps nécessaire pour importer de grandes bases de données, le filtrage correspond à des tâches de nettoyage de données fréquentes, et l’agrégation permet de mesurer l'efficacité lors du traitement de résumés ou de moyennes dans des datasets massifs.
Résultats des tests
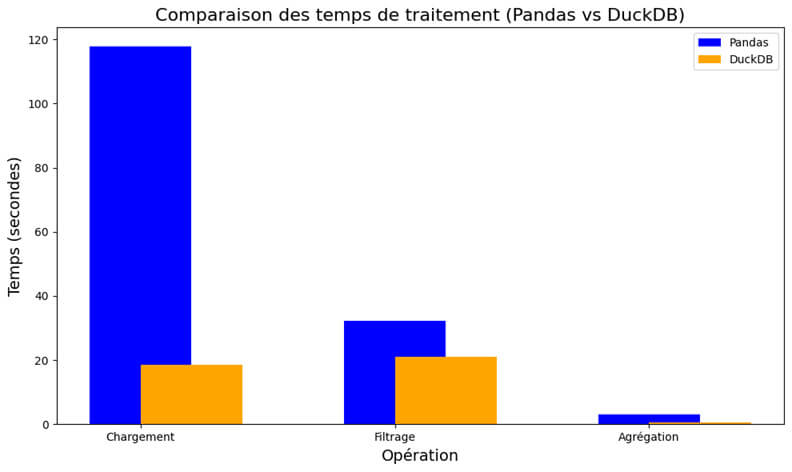
Voici les résultats des tests, qui montrent une différence de performance significative entre Pandas et DuckDB :
| Opération | Pandas | DuckDB |
|---|---|---|
| Temps de chargement | 117.82s | 18.54s |
| Temps de filtrage | 32.12s | 21.01s |
| Temps d'agrégation | 2.97s | 0.60s |
Conclusion
Les résultats parlent d'eux-mêmes : DuckDB surpasse clairement Pandas à chaque étape, avec un temps de chargement des données près de 6 fois plus rapide et des performances supérieures pour le filtrage et l'agrégation. Si Pandas reste parfait pour les petits jeux de données, DuckDB est une option bien plus adaptée quand il s'agit de traiter de grandes quantités de données.
En plus, sa compatibilité avec des outils comme Python et R permet une intégration facile dans des workflows existants. Bien sûr, DuckDB n'est pas conçu pour remplacer Pandas dans tous les cas, notamment pour des besoins BI complexes ou des traitements transactionnels en temps réel, mais il offre une alternative puissante pour maximiser la performance dans les projets de grande envergure. Et avec son développement en pleine croissance, on peut s'attendre à ce que de nouvelles fonctionnalités viennent encore renforcer sa place dans le paysage de la Data Science.
Nos consultants Next Decision sont experts certifiés DuckDB et vous accompagnent dans votre projet DuckDB. Nous pouvons également vous former, Contactez-nous !