
Dans cet article, nous allons explorer l’utilisation de DuckDB, un moteur de base de données relationnelle en colonnes, dans un Data Lakehouse construit autour de données de capteurs IoT.
Un Data Lakehouse est une architecture de gestion des données qui permet de stocker de grandes quantités de données brutes tout en offrant des capacités d'analyse avancées. Il s'agit d'une évolution des datalakes traditionnels, intégrant des fonctionnalités de gestion des données structurées et non structurées.
DuckDB, grâce à sa structure colonnaire, s'intègre parfaitement dans ce type d'architecture pour offrir des performances optimales lors des requêtes analytiques.
dbt (Data Build Tool) est un orchestrateur open-source qui facilite la transformation, le test et la documentation dans les entrepôts de données. Il permet d'automatiser les transformations en SQL et de gérer les dépendances entre celles-ci, simplifiant la gestion des pipelines de données dans un Data Lakehouse.
Architecture de la solution
Notre pipeline de données repose sur un modèle où :
- DBT (Data Build Tool) gère les transformations de données
- DuckDB exécute les requêtes SQL
- Power BI assure la restitution des données pour les analyses BI
Nous avons structuré notre data lakehouse en trois zones principales :
- Zone Bronze : Contient les données brutes au format CSV. Cette zone sert de point d'entrée pour toutes les données collectées.
- Zone Silver : Stocke les données nettoyées et sérialisées au format Parquet. Le format Parquet est idéal pour DuckDB en raison de sa structure colonnaire, permettant des performances élevées lors des opérations de lecture.
- Zone Gold : Contient les agrégations de données et les résultats analytiques, stockés dans une base de données DuckDB. Cette zone est optimisée pour les requêtes rapides et les analyses approfondies.
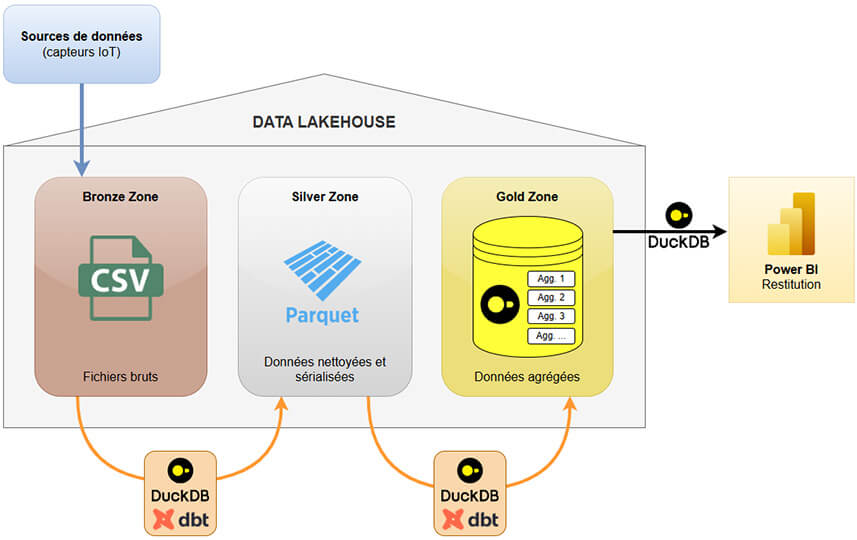
L’ensemble des traitements est réalisé sur une machine locale :
- Moteur SQL : DuckDB 1.1.3
- Orchestration : Python 3.13.1 + dbt Core 1.9 + Adaptateur DuckDB-dbt 1.9.2
- Stockage : Les données sont stockées sur disque local pour notre cas, mais un stockage cloud (Amazon S3, Google Cloud Storage, …) pourrait aussi bien être utilisé.
- Restitution : Microsoft Power BI 2.139 + Connecteur ODBC DuckDB 0.1.5
- Machine : Laptop Intel Core i5 11th gen 16 Go RAM sous Windows 11
Jeu de données
Nous utilisons un jeu de données volumineux composé de relevés horaires de capteurs IoT. Ces capteurs mesurent divers paramètres tels que la température et les vibrations. Le jeu de données comprend :
- Relevés horaires : Un mois de relevés, soit 672 fichiers CSV pour un total d'environ 80 millions d’enregistrements (9,5 Go)
- Informations sur les capteurs : Trois fichiers CSV contenant des détails sur les appareils de mesure, leur type, et leur localisation
Installation de DuckDB et dbt
Installation de DuckDB
Nous exécutons la commande suivante dans le terminal :
C:\Users\gprovent>winget install DuckDB.cli
Installation de Python
Ensuite, nous installons Python en téléchargeant la dernière version stable depuis le site officiel : Python - Télécharger
Création d’un environnement virtuel
Nous créons et activons un environnement virtuel Python (env) dans le dossier de notre projet :
C:\Users\gprovent\demo\duckdb_dbt>py -m venv env
C:\Users\gprovent\demo\duckdb_dbt>env\Scripts\activate
(env) C:\Users\gprovent\demo\duckdb_dbt>env\Scripts\python
Installation de dbt
Nous installons dbt Core et l’adaptateur pour DuckDB à l’aide de gestionnaire de packages Python (pip) :
(env) C:\Users\gprovent\demo\duckdb_dbt>pip install dbt-core dbt-duckdb
dbt-core est le package principal de DBT, tandis que dbt-duckdb permet à DBT d’interagir avec DuckDB en tant que moteur de base de données.
Au préalable de la création de projets avec dbt, nous devons créer un fichier de profils dans notre dossier Utilisateurs, qui regroupera les paramètres de chaque projet dbt :
(env) C:\Users\gprovent>mkdir .dbt
(env) C:\Users\gprovent>cd .dbt
(env) C:\Users\gprovent\.dbt>type NUL > profiles.yml
Création des projets avec dbt
Nous créons 2 projets dbt avec la commande dbt init en ligne de commande :
- Projet bronze_to_silver : Ce projet est responsable du chargement des données de la zone Bronze à la zone Silver. Il est configuré pour s'exécuter chaque heure, assurant ainsi que les nouvelles données sont rapidement disponibles pour les analyses.
(env) C:\Users\gprovent\demo\duckdb_dbt\dbt>dbt init
08:51:24 Running with dbt=1.9.0
Enter a name for your project (letters, digits, underscore): bronze_to_silver
08:51:31
Your new dbt project "bronze_to_silver" was created!
08:51:31 Setting up your profile.
Which database would you like to use?
[1] duckdb
Enter a number: 1
- Projet silver_to_gold : Ce projet agrège les données de la zone Silver vers la zone Gold. Il est actualisé quotidiennement pour fournir des insights analytiques à jour.
(env) C:\Users\gprovent\demo\duckdb_dbt\dbt>dbt init
08:52:34 Running with dbt=1.9.0
Enter a name for your project (letters, digits, underscore): silver_to_gold
08:52:41
Your new dbt project "bronze_to_silver" was created!
08:52:41 Setting up your profile.
Which database would you like to use?
[1] duckdb
Enter a number: 1
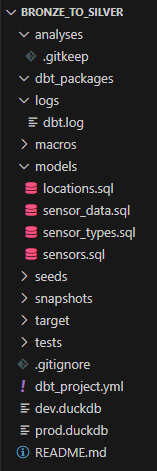
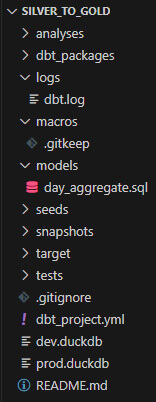
Un dossier est créé pour chacun des projets.
Chaque dossier projet DBT contient :
- Fichier de projet YAML (.yml) : Définit les paramètres du projet
- Requêtes SQL (.sql) : Transforment et agrègent les données
Paramétrage des projets dbt
Après la création des projets, nous éditons le fichier profiles.yml de dbt pour spécifier les chemins de la base de données DuckDB.
Le projet bronze_to_silver n'utilise pas de base de données, tandis que silver_to_gold stocke les données agrégées dans une base DuckDB.
Fichier profiles.yml
bronze_to_silver:
outputs:
dev:
type: duckdb
path: dev.duckdb
threads: 1
prod:
type: duckdb
path: prod.duckdb
threads: 4
target: dev
silver_to_gold:
outputs:
dev:
type: duckdb
path: "C:/Users/gprovent/demo/duckdb_dbt/lakehouse/gold/goldbase.duckdb"
threads: 1
prod:
type: duckdb
path: "C:/Users/gprovent/demo/duckdb_dbt/lakehouse/gold/goldbase.duckdb"
threads: 4
target: dev
Ici nous utiliserons la même base pour l’environnement de développement et celui de production.
Création de la base de données DuckDB (Zone Gold)
Nous créons la base de données vierge goldbase .duckdb en nous plaçant dans le répertoire de la gold zone et en exécutant dans le terminal la commande (lancement de DuckDB en créant la base) :
C:\Users\gprovent\demo\duckdb_dbt\lakehouse\gold>duckdb goldbase.duckdb
v1.1.3 19864453f7
Enter ".help" for usage hints.
D .quit
Flux bronze to silver
Fichier projet
Nous mettons à jour le fichier dbt_project.yml, précisant les paramètres du projet, notamment les variables contenant les chemins d’accès aux zones Bronze et Silver du Data Lakehouse :
# Nom et version du projet :
name: 'bronze_to_silver'
version: '1.0.0'
# Profil associé :
profile: 'bronze_to_silver'
# Définition des dossiers du projet :
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
# Dossiers à supprimer avec 'dbt clean' :
clean-targets:
- "target"
- "dbt_packages"
# Définition des variables :
vars :
paths:
# Chemin d'accès de la zone bronze :
bronze_path: "C:/Users/gprovent/demo/duckdb_dbt/lakehouse/bronze/"
# Chemin d'accès de la zone silver :
silver_path: "C:/Users/gprovent/demo/duckdb_dbt/lakehouse/silver/"
Requêtes
Nous créons ensuite dans le dossier ~\models les requêtes SQL qui serviront à alimenter la zone Silver du Data Lakehouse :
- sensor_data.sql (relevés de mesures)
- locations.sql (localisation des capteurs)
- sensor_types.sql (type de capteurs)
- sensors.sql (informations sur les capteurs)
Relevés de mesures :
-- Définition des variables :
-- Date du jour
{% if execute %}
{% set result = run_query("SELECT REPLACE(CAST(CURRENT_DATE AS STRING), '-', '')") %}
{% set date_str = result.columns[0].values()[0] %}
{% endif %}
-- Chemin d'accès des fichiers d'entrée/sortie
{% set bronze_files = var('paths')['bronze_path'] ~ "sensor_data_" ~ date_str ~ "_*.csv" %}
{% set silver_file = var('paths')['silver_path'] ~ "f_sensor_data_" ~ date_str ~ ".parquet" %}
-- Configuration de l'output :
{{ config(materialized='external', location=silver_file) }}
-- Requête :
SELECT *
FROM read_csv_auto('{{ bronze_files }}')
Informations sur les capteurs :
-- Définition des variables :
{% set sensors_file = var('paths')['bronze_path'] ~ "sensors.csv" %}
{% set silver_file = var('paths')['silver_path'] ~ "d_sensors.parquet" %}
-- Configuration de l'output :
{{ config(materialized='external', location=silver_file) }}
-- Sérialisation des CSV en format parquet :
SELECT *
FROM read_csv_auto('{{ sensors_file }}')
Types de capteurs :
-- Définition des variables :
{% set sensor_types_file = var('paths')['bronze_path'] ~ "sensor_types.csv" %}
{% set silver_file = var('paths')['silver_path'] ~ "d_sensor_types.parquet" %}
-- Configuration de l'output :
{{ config(materialized='external', location=silver_file) }}
-- Sérialisation des CSV en format parquet :
SELECT *
FROM read_csv_auto('{{ sensor_types_file }}')
Localisation des capteurs :
-- Définition des variables :
{% set locations_file = var('paths')['bronze_path'] ~ "locations.csv" %}
{% set silver_file = var('paths')['silver_path'] ~ "d_locations.parquet" %}
-- Configuration de l'output :
{{ config(materialized='external', location=silver_file) }}
-- Sérialisation des CSV en format parquet :
SELECT *
FROM read_csv_auto('{{ locations_file }}')
Flux Silver to Gold
Fichier projet
Nous mettons à jour le fichier dbt_project.yml : :
# Nom et version du projet :
name: 'silver_to_gold'
version: '1.0.0'
# Profil associé :
profile: 'silver_to_gold'
# Définition des dossiers du projet :
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
# Dossiers à supprimer avec 'dbt clean' :
clean-targets:
- "target"
- "dbt_packages"
# Définition des variables :
vars :
paths:
# Chemin d'accès de la zone silver :
silver_path: "C:/Users/gprovent/demo/duckdb_dbt/lakehouse/silver/"
# Chemin d'accès de la zone gold :
bronze_path: "C:/Users/gprovent/demo/duckdb_dbt/lakehouse/gold/"
Requête
Nous créons ensuite dans le dossier ~\models la requête d’agrégation qui servira à alimenter la base de données de la zone Gold du Data Lakehouse (elle contient groupements, agrégations et jointures avec les tables de dimensions) :
-- Définition des variables :
-- Chemin d'acèès des fichiers d'entrée
{% set silver_files = var('paths')['silver_path'] ~ "f_sensor_data*.parquet" %}
{% set locations = var('paths')['silver_path'] ~ "d_locations.parquet" %}
{% set sensor_types = var('paths')['silver_path'] ~ "d_sensor_types.parquet" %}
{% set sensors = var('paths')['silver_path'] ~ "d_sensors.parquet" %}
-- Chemin d'accès pour la sortie
{% set gold_file = var('paths')['gold_path'] ~ "a_day_aggregate.parquet" %}
-- Configuration du format de sortie :
{{ config(materialized='table') }}
-- Requête :
SELECT
date_trunc('day', si.timestamp) AS day,
l.commercial_zone,
st.description AS sensor_type,
se.manufacturer,
l.type AS location_type,
avg(si.temperature) AS avg_temperature,
min(si.temperature) AS min_temperature,
max(si.temperature) AS max_temperature,
avg(si.rpm) AS avg_rpm,
avg(si.vibration_x) AS avg_vibration_x,
avg(si.vibration_y) AS avg_vibration_y,
avg(si.vibration_z) AS avg_vibration_z
FROM read_parquet('{{ silver_files }}') AS si
LEFT JOIN read_parquet('{{ sensors }}') AS se ON se.sensor_id = si.sensor_id
LEFT JOIN read_parquet('{{ sensor_types }}') AS st ON st.type_id = se.type_id
LEFT JOIN read_parquet('{{ locations }}') AS l ON si.location_id = l.location_id
GROUP BY day, l.commercial_zone, sensor_type, se.manufacturer, location_type
ORDER BY day DESC
Exécution des projets dbt
Les deux projets peuvent maintenant être exécutés afin d’alimenter les zones Silver et Gold du Data Lakehouse, avec la commande (à exécuter dans le dossier de chaque projet) :
- dbt run (sur l’environnement de développement)
- dbt run –-target prod (sur l’environnement de production)
Bronze to Silver
Exécution pour une journée de relevés :
(env) C:\Users\gprovent\demo\duckdb_dbt\dbt\bronze_to_silver>dbt run --target prod
15:05:09 Running with dbt=1.9.0
15:05:09 Registered adapter: duckdb=1.9.2
15:05:10 Found 4 models, 426 macros
15:05:10
15:05:10 Concurrency: 4 threads (target='prod')
15:05:10
15:05:10 1 of 4 START sql external model main.locations ............. [RUN]
15:05:10 3 of 4 START sql external model main.sensor_types .......... [RUN]
15:05:10 2 of 4 START sql external model main.sensor_data ........... [RUN]
15:05:10 4 of 4 START sql external model main.sensors ............... [RUN]
15:05:10 1 of 4 OK created sql external model main.locations ........ [OK in 0.18s]
15:05:10 3 of 4 OK created sql external model main.sensor_types ..... [OK in 0.19s]
15:05:10 4 of 4 OK created sql external model main.sensors .......... [OK in 0.25s]
15:05:13 2 of 4 OK created sql external model main.sensor_data ...... [OK in 3.18s]
15:05:13
15:05:13 Finished running 4 external models in 0 hours 0 minutes and 3.34 seconds (3.34s).
15:05:13
15:05:13 Completed successfully
15:05:13
15:05:13 Done. PASS=4 WARN=0 ERROR=0 SKIP=0 TOTAL=4
Le temps d’exécution constaté en environnement de production est d’environ 3,5 secondes par journée de relevés (24 fichiers CSV, 2 880 000 lignes)
Silver to Gold
(env) C:\Users\gprovent\demo\duckdb_dbt\dbt\silver_to_gold>dbt run --target prod
15:10:48 Running with dbt=1.9.0
15:10:48 Registered adapter: duckdb=1.9.2
15:10:49 Unable to do partial parsing because saved manifest not found. Starting full parse.
15:10:49 Found 1 model, 426 macros
15:10:49
15:10:49 Concurrency: 4 threads (target='prod')
15:10:49
15:10:50 1 of 1 START sql table model main.day_aggregate ............ [RUN]
15:10:55 1 of 1 OK created sql table model main.day_aggregate ....... [OK in 5.28s]
15:10:55
15:10:55 Finished running 1 table model in 0 hours 0 minutes and 5.43 seconds (5.43s).
15:10:55
15:10:55 Completed successfully
15:10:55
15:10:55 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
Le temps d’exécution constaté en environnement de production est d’environ 5,5 secondes pour ~80 000 000 d’enregistrements agrégés.
Contenu du Data Lakehouse
Après exécution des 2 pipelines, chacune des zones du Data Lakehouse a été alimentée.
Zone Bronze :
675 éléments (24 fichiers par jour + 3 fichiers de dimensions)
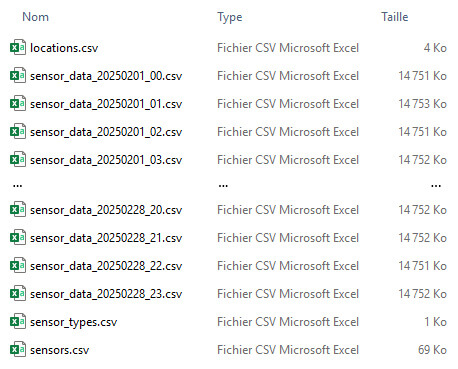
Zone Silver :
31 éléments (un fichier par jour + 3 fichiers de dimensions)
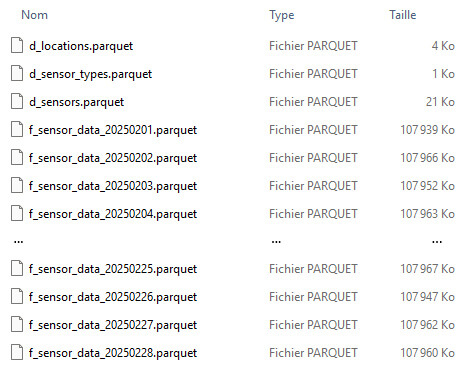
Zone Gold :
1 fichier base de données

Connnexion de Power BI à la base DuckDB
Installation du pilote ODBC de DuckDB
Nous téléchargeons le dernier pilote ODBC DuckDB pour Windows à partir de :
Releases · MotherDuck-Open-Source/duckdb-power-query-connector
(fichier duckdb_odbc-windows-amd64.zip)
Nous extrayons le zip, et exécutons le fichier odbc_install.exe (Windows peut afficher un avertissement de sécurité, auquel cas cliquer sur "Informations complémentaires", puis "Exécuter quand même").
Connexion à la base DuckDB
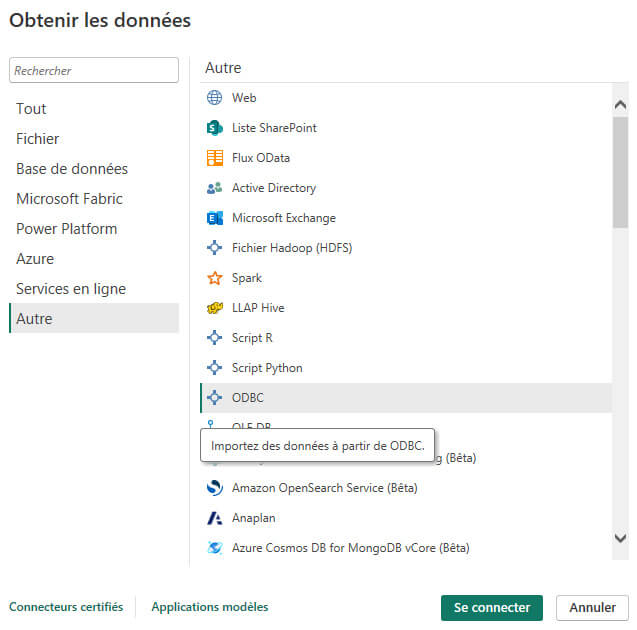
Nous créons un nouveau projet dans Power BI, et cliquons sur « Obtenir les données » dans le ruban Accueil :

Nous nous connectons à une nouvelle source de données en sélectionnant "Autre" puis "ODBC" :
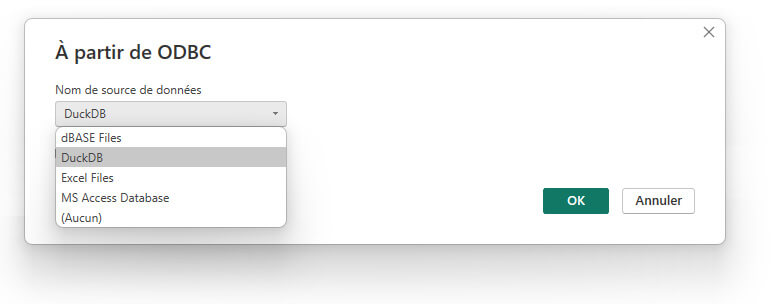
Si le pilote a bien été installé, vous devriez avoir une entrée pour DuckDB dans la liste déroulante :
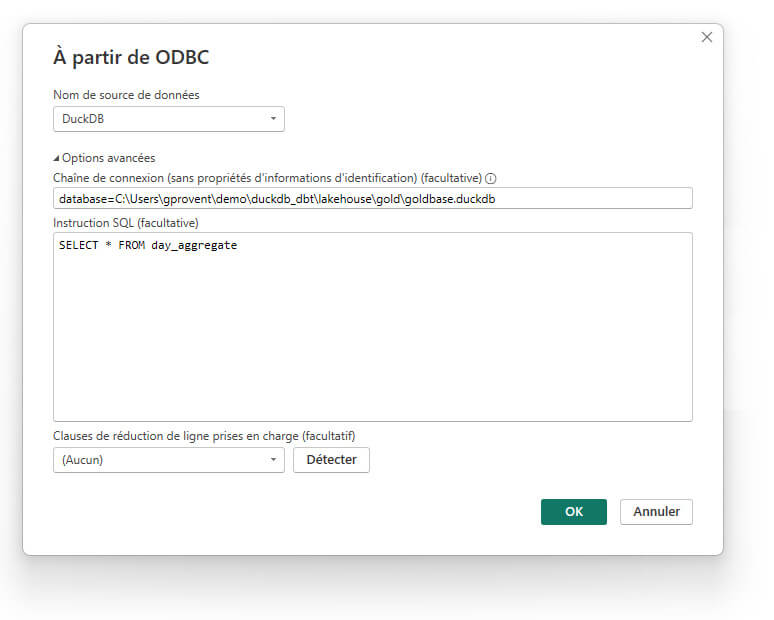
Dans les Options avancées, nous renseignons la Chaîne de connexion avec le chemin d’accès à la base de données DuckDB :
database=C:\Users\gprovent\demo\duckdb_dbt\lakehouse\gold\goldbase.duckdb
Et nous définissons l'Instruction SQL qui sera traitée par DuckDB, à savoir le chargement de l’une (ou plusieurs) des tables agrégées de la base DuckDB, ici la table day_aggregate :
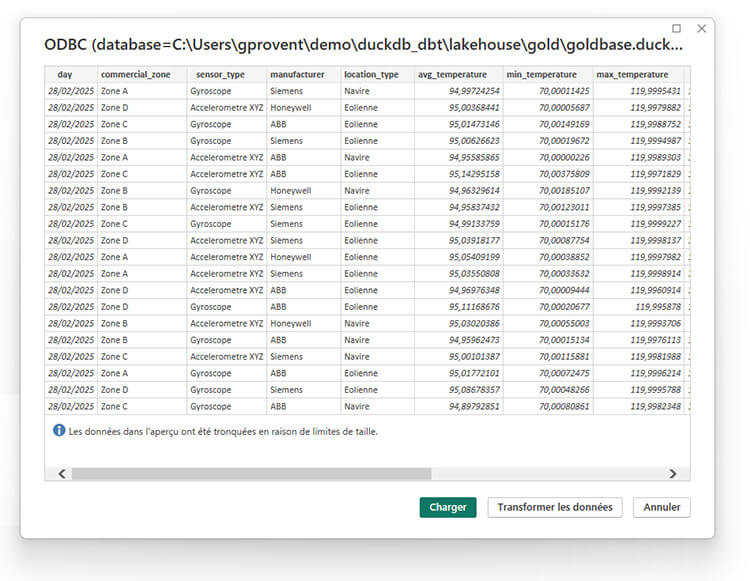
SELECT * FROM day_aggregate
Les données de la table day_aggregate peuvent maintenant être chargées et utilisées dans Power BI.
Conclusion
DuckDB se distingue comme une solution robuste et efficace pour les analyses de données dans un environnement de Data Lakehouse. Ses performances exceptionnelles, notamment grâce à son architecture en colonnes, en font un choix idéal pour les environnements où les données sont stockées localement et où des requêtes analytiques rapides sont nécessaires.
Avantages de DuckDB
- Performance optimale : DuckDB excelle dans les opérations de lecture, ce qui est crucial pour les analyses de données. Sa capacité à traiter rapidement de grandes quantités de données permet d'obtenir des insights en temps réel, essentiels pour la prise de décision.
- Simplicité d'intégration : L'intégration de DuckDB avec des outils comme DBT et Power BI est relativement simple. Cela permet de créer des pipelines de données fluides et efficaces, réduisant ainsi le temps et les efforts nécessaires pour configurer et maintenir le système.
- Compatibilité avec SQL : La compatibilité de DuckDB avec SQL facilite son adoption par les utilisateurs familiers avec ce langage. Cela réduit la courbe d'apprentissage et permet une transition en douceur depuis d'autres systèmes de gestion de bases de données.
- Efficacité en lecture : Le format Parquet, utilisé dans la zone Silver, est parfaitement adapté à DuckDB. Cette compatibilité permet des lectures rapides et efficaces des données, optimisant ainsi les performances globales du système.
Considérations et Limites
- Scalabilité : DuckDB est conçu pour fonctionner sur une seule machine, ce qui peut limiter sa capacité à gérer des volumes de données extrêmement élevés ou des environnements nécessitant une scalabilité horizontale. Pour des scénarios nécessitant une telle scalabilité, des solutions distribuées pourraient être plus appropriées.
- Gestion de la concurrence : Bien que DuckDB soit performant pour les requêtes analytiques, il n'est pas optimisé pour gérer un grand nombre de connexions simultanées. Cela peut poser des défis dans des environnements multi-utilisateurs où de nombreuses requêtes doivent être traitées en parallèle.
- Écriture de données : DuckDB est principalement optimisé pour les opérations de lecture. Pour les scénarios nécessitant de fréquentes mises à jour de données, d'autres solutions pourraient offrir de meilleures performances en écriture.
- Fonctionnalités avancées : Bien que DuckDB supporte de nombreuses fonctionnalités SQL, il peut manquer certaines fonctionnalités avancées disponibles dans d'autres SGBDR plus matures. Il est donc important d'évaluer les besoins spécifiques de votre projet avant de choisir DuckDB.
En conclusion, DuckDB offre une solution puissante et flexible pour les analyses de données dans un data lakehouse, à condition de bien évaluer ses limites et de l'intégrer dans un environnement adapté à ses capacités.
Nos consultants Next Decision sont experts certifiés DuckDB et vous accompagnent dans votre projet DuckDB. Nous pouvons également vous former, Contactez-nous !